
Kernel Ventures: Exploring Data Availability — In Relation to Historical Data Layer Design

 Blockchain is moving towards reducing data redundancy as well as multi-chain division of labor. This article explores the existing DA Solutions and Historical Data Layer Design.
Blockchain is moving towards reducing data redundancy as well as multi-chain division of labor. This article explores the existing DA Solutions and Historical Data Layer Design.

Author: Kernel Ventures Jerry Luo
Editor(s): Kernel Ventures Rose, Kernel Ventures Mandy, Kernel Ventures Joshua
TLDR:
- In the early stage of blockchain, maintaining data consistency is considered extremely important to ensure security and decentralization. However, with the development of the blockchain ecosystem, the storage pressure is also increasing, leading to a trend of centralization in node operation. Such being the case, the storage cost problem brought by TPS growth in Layer1 needs to be solved urgently.
- Faced with this problem, developers should propose a solution that takes security, storage cost, data reading speed, and DA layer versatility fully into account.
- In the process of solving this problem, many new technologies and ideas have emerged, including Sharding, DAS, Verkle Tree, DA intermediate components, and so on. They try to optimize the storage scheme of the DA layer by reducing data redundancy and improving data validation efficiency.
- DA solutions are broadly categorized into two types from the perspective of data storage location, namely, main-chain DAs and third-party DAs. Main-chain DAs are designed from the perspectives of regular data cleansing and sliced data storage to reduce the storage pressure on nodes, while the third-party DAs are designed to serve the storage needs which have reasonable solutions for large amounts of data. As a result, we mainly trade-off between single-chain compatibility and multi-chain compatibility in third-party DAs, and propose three kinds of solutions: main-chain-specific DAs, modularized DAs, and storage public-chain DAs.
- Payment-type public chains have very high requirements for historical data security and, thus are suitable to use the main chain as the DA layer. However, for public chains that have been running for a long time and have a large number of miners running the network, it is more suitable to adopt a third-party DA that does not involve the consensus layer change with relatively high security. For comprehensive public chains, it is more suitable to use the main chain's dedicated DA storage with larger data capacity, lower cost, and security. However, considering the demand for cross-chain, modular DA is also a good option.
- Overall, blockchain is moving towards reducing data redundancy as well as multi-chain division of labor.
Background
Blockchain, as a distributed ledger, needs to make a copy of the historical data stored on all nodes to ensure that the data storage is secure and sufficiently decentralized. Since the correctness of each state change is related to the previous state (the source of the transaction), in order to ensure the correctness of the transaction, a blockchain should store all the history of transactions from the generation of the first transaction to the current transaction. Taking Ethereum as an example, even taking 20 kb per block as the average size, the total size of the current data in Ethereum has reached 370 GB. For a full node, in addition to the block itself, it has to record the state and transaction receipts. Including this part, the total amount of storage of a single node has exceeded 1 TB, which makes the operation of the node gradually centralized.
The recent Cancun upgrade of Ethereum aims to increase Ethereum's TPS to near 1000, at which point Ethereum's annual storage growth will exceed the sum of its current storage. In high-performance public chains, the transaction speed of tens of thousands of TPS may bring hundreds of GB of data addition per day. The common data redundancy of all nodes on the network obviously can not adapt to such storage pressure. So, Layer1 must find a suitable solution to balance the TPS growth and the storage cost of the nodes.
Performance Indicators of DA
Safety
Compared with a database or linked list, blockchain's immutability comes from the fact that its newly generated data can be verified by historical data, thus ensuring the security of its historical data is the first issue to be considered in DA layer storage. To judge the data security of blockchain systems, we often analyze the redundancy amount of data and the checking method of data availability.
- Number of redundancy:
The redundancy of data in the blockchain system mainly plays such roles: first, more redundancy in the network can provide more samples for reference when the verifier needs to check the account status which can help the node select the data recorded by the majority of nodes with higher security. In traditional databases, since the data is only stored in the form of key-value pairs in a certain node, changing the historical data is only carried out in a single node, with a low cost of the attack, and theoretically, the more the number of redundancies is, the higher the degree of credibility of the data is. Theoretically, the more redundancy there is, the more trustworthy the data will be. What's more, the more nodes there are, the less likely the data will be lost. This point can also be compared to the centralized servers that store Web2 games, once the background servers are all shut down, there will be a complete closure of the service. But it is not better with more redundancy, because redundancy will bring additional storage space, which will bring too much storage pressure to the system. A good DA layer should choose a suitable redundancy way to strike a balance between security and storage efficiency.
- Data Availability Checking:
The amount of redundancy can ensure enough records of data in the network, but the data to be used must be checked for accuracy and completeness. Current blockchains commonly use cryptographic commitment algorithms as the verification methods, which just keep a small cryptographic commitment obtained by transaction data mixing, for the whole network to record. To test the authenticity of historical data, we should try to recover the commitment with the data. If the recovery commitment is identical to the original commitment, the verification passes. Commonly used cryptographic verification algorithms are Merkle Root and Verkle Root. High-security data availability verification algorithms can quickly verify historical data with the help of as little third-party data as possible.
Storage Cost
After ensuring basic security, the next goal of the DA layer is to reduce costs and increase efficiency. The first step is to reduce the storage cost presented by the memory consumption caused by storing data per unit size, regardless of the difference in hardware performance. Nowadays, the main ways to reduce storage costs in blockchain are to adopt sharding technology and use reward storage to reduce the number of data backups while keeping its security. However, it is not difficult to see from the above improvement methods that there is a game relationship between storage cost and data security, and reducing storage occupancy often means a decrease in security. Therefore, an excellent DA layer needs to realize the balance between storage cost and data security. In addition, if the DA layer is a separate public chain, it also needs to reduce the cost by minimizing the intermediate process of data exchange, in which every transit process needs to leave index data for subsequent retrieval. So the longer the calling process, the more index data will be left, which will increase the storage cost. Finally, the cost of storing data is directly linked to the persistence of the data. In general, the higher the cost of data storage, the more difficult it is for the public chain to store data persistently.
Data Reading Speed
Having achieved cost reduction, the next step is efficiency which means the ability to quickly recall data from the DA layer when needed. This process involves two steps, the first is to search for nodes to store data, mainly for public chains that have not achieved data consistency across the network, if the public chain has achieved data synchronization of nodes across the network, the time consumption of this process can be ignored. Then, in the mainstream blockchain systems at this stage, including Bitcoin, Ethereum, and Filecoin, the nodes' storage method is all Leveldb database. In Leveldb, data is stored in three ways. First, data written on-the-fly is stored in Memtable type files until the Memtable is full, then, the file type is changed from Memtable to Immutable Memtable. Both two types are stored in memory, but Immutable Memtable files are read-only. The hot storage used in the IPFS network stores data in this part of the network, so that it can be quickly read from memory when it is called, but an average node only has GBs of removable memory, which can easily be slowed down, and when a node goes down, the data in memory is lost permanently. If you want persistent data storage, you need to store the data in the form of SST files on the solid state disk (SSD), but when reading the data, you need to read the data to the memory first, which greatly reduces the speed of data indexing. Finally, for a system with storage sharding, data restoration requires sending data requests to multiple nodes and restoring them, a process that also slows down the reading of data.

DA Layer Generalization
With the development of DeFi and various problems of CEX, users' requirements for cross-chain transactions of decentralized assets are growing. Whether we adopt the cross-chain mechanism of hash-locking, notary, or relay chain, we can't avoid the simultaneous determination of historical data on two chains. The key to this problem lies in the separation of data on the two chains, which cannot be directly communicated in different decentralized systems. Therefore, a solution is proposed by changing the storage method of the DA layer, which stores the historical data of multiple public chains on the same trusted public chain and only needs to call the data on this public chain when verifying. This requires the DA layer to be able to establish secure communication with different types of public chains which means that the DA layer has good versatility.
Techniques Concerning DA
Sharding
In traditional distributed systems, a file is not stored in a complete form on a node, but to divide original data into multiple blocks and store them in each node. Also, the block is often not only stored in one node but leaves appropriate backup in other nodes. In the existing mainstream distributed systems, the number of backups is usually set to 2. This sharding mechanism can reduce the storage pressure of individual nodes, expand the total capacity of the system to the sum of the storage capacity of each node, and at the same time ensure the security of storage through appropriate data redundancy. The sharding scheme adopted in blockchain is generally similar to the traditional distributed systems, but there are differences in some details. Firstly, since the default nodes in the blockchain are untrustworthy, the process of realizing sharding requires a sufficiently large amount of data backups for the subsequent judgment of data authenticity, so the number of backups of this node needs to be much more than 2. Ideally, in the blockchain system that adopts this scheme of storage, if the total number of authentication nodes is T and the number of shards is N, the number of backups should be T/N. Secondly, as to the storage process of a block, a traditional distributed system with fewer nodes often has the mode that a node adapted to multiple data blocks. Firstly, the data is mapped to the hash ring by the consistent hash algorithm, then each node stores a certain range of numbered blocks with the hash ring's assignments. It can be accepted in the system that one single node does not have a storage task in certain storage. While on the blockchain, the storage block is no longer a random but an inevitable event for the nodes. Each node will randomly select a block for storage in the blockchain, with the process completed by the hashing result of data mixed with the node's information to modulo slice number. Assuming that each data is divided into N blocks, the actual storage size of each node is only 1/N. By setting N appropriately, we can achieve a balance between the growth of TPS and the pressure on node storage.
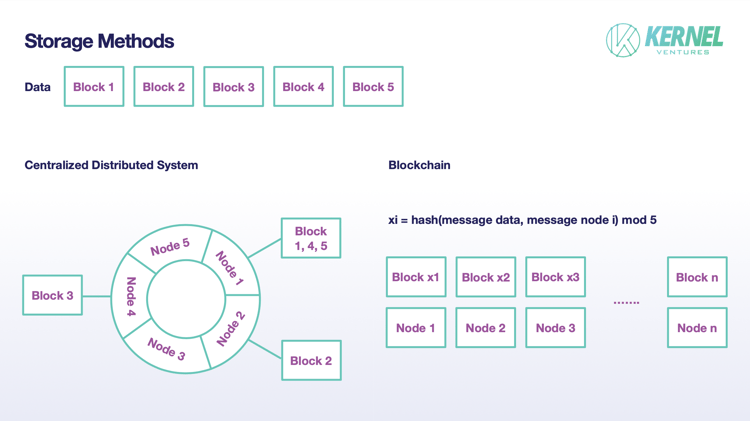
DAS (Data Availability Sampling)
DAS technology is a further optimization of the storage method based on sharding. In the process of sharding, due to the simple random storage of nodes, a block loss may occur. Secondly, for the data after sharding, how to confirm the authenticity and integrity of the data during the restoration process is also very important. In DAS, these two problems are solved by Eraser code and KZG polynomial commitment.
- Eraser code:
Given the large number of verified nodes in Ethereum, it's possible that a block is not being stored by any node although it is a probability event. To mitigate the threat of missing storage, instead of slicing and dicing the raw data into blocks, this scheme maps the raw data to the coefficients of an nth-degree polynomial, then takes 2n points on the polynomial and lets the nodes randomly choose one of them to store. For this nth-degree polynomial, only n+1 points are needed for the reduction, and thus only half of the blocks need to be selected by the nodes for us to realize the reduction of the original data. The Eraser code improves the security of the data storage and the network's ability to recover the data.
- KZG polynomial commitment:
A very important aspect of data storage is the verification of data authenticity. In networks that do not use Eraser code, various methods can be used for verification, but if the Eraser code above is introduced to improve data security, then it is more appropriate to use the KZG polynomial commitment, which can verify the contents of a single block directly in the form of a polynomial, thus eliminating the need to reduce the polynomial to binary data. KZG polynomial commitment can directly verify the content of a single block in the form of polynomials, thus eliminating the need to reduce the polynomials to binary data, and the overall form of verification is similar to that of Merkle Tree, but it does not require specific Path node data and only requires the KZG Root and block data to verify the authenticity of the block.
Data Validation Method in DA
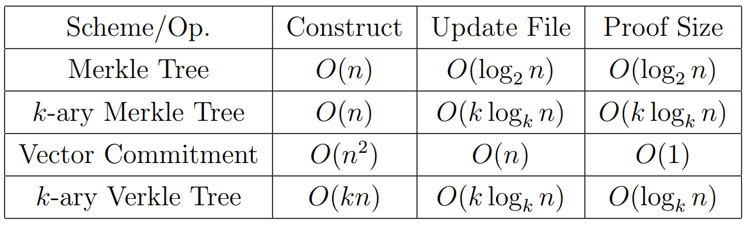
Data validation ensures that the data called from a node are accurate and complete. To minimize the amount of data and computational cost required in the validation process, the DA layer now uses a tree structure as the mainstream validation method. The simplest form is to use Merkle Tree for verification, which uses the form of complete binary tree records, only need to keep a Merkle Root and the hash value of the subtree on the other side of the path of the node can be verified, the time complexity of the verification is O(logN) level (the logN is default log2(N)). Although the validation process has been greatly simplified, the amount of data for the validation process in general still grows with the increase of data. To solve the problem of increasing validation volume, another validation method, Verkle Tree, is proposed at this stage, in which each node in the Verkle Tree not only stores the value but also attaches a Vector Commitment, which can quickly validate the authenticity of the data by using the value of the original node and the commitment proof, without the need to call the values of other sister nodes, which makes the computation of each validation easier and faster. This makes the number of computations for each verification only related to the depth of the Verkle Tree, which is a fixed constant, thus greatly accelerating the verification speed. However, the calculation of Vector Commitment requires the participation of all sister nodes in the same layer, which greatly increases the cost of writing and changing data. However, for data such as historical data, which is permanently stored and cannot be tampered with, also, can only be read but not written, the Verkle Tree is extremely suitable. In addition, Merkle Tree and Verkle Tree itself have a K-ary form of variants, the specific implementation of the mechanism is similar, just change the number of subtrees under each node, the specific performance comparison can be seen in the following table.
Generic DA Middleware
The continuous expansion of the blockchain ecosystem has brought about an increasing number of public chains. Due to the advantages and irreplaceability of each public chain in their respective fields, it is impossible for Layer1 public chains to become unified in a short time. However, with the development of DeFi and the problems of CEX, users' demand for decentralized cross-chain trading assets is growing. Therefore, DA layer multi-chain data storage, which can eliminate the security problems in cross-chain data interaction, has gained more and more attention. However, to accept historical data from different public chains, it is necessary for the DA layer to provide decentralized protocols for standardized storage and validation of data flow. For example, kvye, a storage middleware based on Arweave, adopts the method of actively crawling data from the main chains, and it can store the data from all the chains in a standardized form to Arweave in order to minimize the differences in the data transmission process. Comparatively speaking, Layer2, which specializes in providing DA layer data storage for a certain public chain, carries out data interaction by way of internal shared nodes. Although it reduces the cost of interaction and improves security, it has greater limitations and can only provide services to specific public chains.
Storage Methods of DA
Main Chain DA
DankSharding-like
There is no definitive name for this type of storage scheme, but the most prominent one is Dank Sharding on Ethereum, so in this paper, we use the term Dank Sharding-like to refer to this type of scheme. This type of scheme mainly uses the two DA storage techniques mentioned above, sharding and DAS, firstly, the data is divided into an appropriate number of shares by sharding, and then each node extracts a data block in the form of DAS for storage. For the case that there are enough nodes in the whole network, we can take a larger number of slices N, so that the storage pressure of each node is only 1/N of the original, thus realizing N-fold expansion of the overall storage space. At the same time, to prevent the extreme case that a block is not stored by any block, Dank Sharding encodes the data using Eraser Code, which requires only half of the data for complete restoration. Lastly, the data is verified using a Verkle Tree structure with polynomial commitments for fast checksums.
Temporary Storage
For the DA of the main chain, one of the simplest ways to handle data is to store historical data for a short period of time. Essentially, the blockchain acts as a public ledger, where changes are made to the content of the ledger in the presence of the entire network, and there is no need for permanent storage. In the case of Solana, for example, although its historical data is synchronized to Arweave, the main network nodes only retain the transaction data of the last two days. On a public chain based on account records, each moment of historical data retains the final state of the account on the blockchain, which is sufficient to provide a basis for verification of changes at the next moment. Those who have special needs for data before this time, can store it on other decentralized public chains or hand it over to a trusted third party. In other words, those who have additional needs for data will need to pay for historical data storage.
Third-Party DA
DA for Main Chain: EthStorage
- DA for Main Chain:
The most important thing for the DA layer is the security of data transmission, and the DA with the highest security is the DA of the main chain, but the main chain storage is limited by the storage space and the competition of resources, so when the data volume of the network grows fast, the third-party DA is a better choice if it wants to realize the long-term storage of data. If the third-party DA has higher compatibility with the main network, it can realize the sharing of nodes, and the data interaction process will have higher security. Therefore, under the premise of considering security, a dedicated DA for the main chain will have a huge advantage. Taking Ethereum as an example, one of the basic requirements for a DA dedicated to the main chain is that it can be compatible with EVM to ensure interoperability with Ethereum data and contracts, and representative projects include Topia, EthStorage, etc. Among them, EthStorage is the most compatible DA in terms of compatibility. Representative projects include Topia, EthStorage, and so on. Among them, EthStorage is the most well-developed in terms of compatibility, because in addition to EVM compatibility, it has also set up relevant interfaces to interface with Remix, Hardhat, and other Ethereum development tools to realize compatibility with Ethereum development tools.
- EthStorage:
EthStorage is a public chain independent of Ethereum, but the nodes running on it are a supergroup of Ethereum nodes, which means that the nodes running EthStorage can also run Ethereum at the same time. What's more, we can also directly operate EthStorage through the opcodes on Ethereum. EthStorage's storage model retains only a small amount of metadata for indexing on the main Ethereum network, essentially creating a decentralized database for Ethereum. In the current solution, EthStorage deploys an EthStorage Contract on the main Ethereum to realize the interaction between the main Ethereum and EthStorage. If Ethereum wants to deposit data, it needs to call the put() function in the contract, and the input parameters are two-byte variables key, data, where data represents the data to be deposited, and the key is its identity in the Ethereum network, which can be regarded as similar to the existence of CID in IPFS. After the (key, data) data pair is successfully stored in the EthStorage network, EthStorage will generate a kvldx to be returned to the Ethereum host network, which corresponds to the key on the Ethereum network, and this value corresponds to the storage address of the data on EthStorage so that the original problem of storing a large amount of data can now be changed to storing a single (key, kvldx). (key, kvldx) pair, which greatly reduces the storage cost of the main Ethereum network. If you need to call the previously stored data, you need to use the get() function in EthStorage and enter the key parameter, and then you can do a quick lookup of the data on EthStorage by using the kvldx stored in Ethereum.
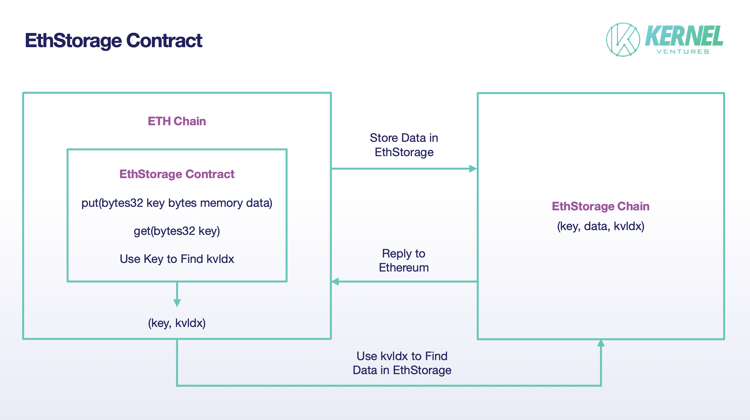
In terms of how nodes store data, EthStorage learns from the Arweave model. First of all, a large number of (k,v) pairs from ETH are sharded, and each sharding contains a fixed number of (k, v) pairs, of which there is a limit on the size of each (k, v) pair to ensure the fairness of workload in the process of storing rewards for miners. For the issuance of rewards, it is necessary to verify whether the node stores data to begin with. In this process, EthStorage will divide a sharding (TB size) into many chunks and keep a Merkle root on the Ethereum mainnet for verification. Then the miner needs to provide a nonce to generate a few chunks by a random algorithm with the hash of the previous block on EthStorage, and the miner needs to provide the data of these chunks to prove that he/she has stored the whole sharding, but this nonce can not be chosen arbitrarily, or else the node will choose the appropriate nonce corresponding to the chunks stored by him/her and pass the verification. However, this nonce cannot be chosen randomly, otherwise the node will choose a suitable nonce that corresponds only to its stored chunks and thus pass the verification, so this nonce must make the generated chunks after mixing and hashing so that the difficulty value meets the requirements of the network, and only the first node that submits the nonce and the random-access proof can get the reward.
Modularization DA: Celsetia
- Blockchain Module:
The transactions to be performed on the Layer1 public chain are divided into the following four parts: (1) designing the underlying logic of the network, selecting validation nodes in a certain way, writing blocks, and allocating rewards for network maintainers; (2) packaging and processing transactions and publishing related transactions; (3) validating transactions to be uploaded to the blockchain and determining the final status; (4) storing and maintaining historical data on the blockchain. According to the different functions performed, we can divide the blockchain into four modules, consensus layer, execution layer, settlement layer, and data availability layer (DA layer).
- Modular Blockchain design:
For a long time, these four modules have been integrated into a single public chain, such a blockchain is called a monolithic blockchain. This form is more stable and easier to maintain, but it also puts tremendous pressure on the single public chain. In practice, the four modules constrain each other and compete for the limited computational and storage resources of the public chain. For example, increasing the processing speed of the processing layer will bring more storage pressure to the data availability layer; ensuring the security of the execution layer requires a more complex verification mechanism but slows down the speed of transaction processing. Therefore, the development of a public chain often faces a trade-off between these four modules. To break through this bottleneck of public chain performance improvement, developers have proposed a modular blockchain solution. The core idea of modular blockchain is to strip out one or several of the four modules mentioned above and give them to a separate public chain for implementation. In this way, the public chain can focus on the improvement of transaction speed or storage capacity, breaking through the previous limitations on the overall performance of the blockchain due to the short board effect.
- Modular DA:
The complex approach of separating the DA layer from the blockchain business and placing it on a separate public chain is considered a viable solution for Layer1's growing historical data. At this stage, the exploration in this area is still at an early stage, and the most representative project is Celestia, which uses the storage method of Sharding, which also divides the data into multiple blocks, and each node extracts a part of it for storage and uses the KZG polynomial commitment to verify the data integrity. At the same time, Celestia uses advanced two-dimensional RS corrective codes to rewrite the original data in the form of a k*k matrix, which ultimately requires only 25% of the original data to be recovered. However, sliced data storage is essentially just multiplying the storage pressure of nodes across the network by a factor of the total data volume, and the storage pressure of nodes still grows linearly with the data volume. As Layer1 continues to improve for transaction speed, the storage pressure on nodes may still reach an unacceptable threshold someday. To address this issue, an IPLD component is introduced in Celestia. Instead of storing the data in the k*k matrix directly on Celestia, the data is stored in the LL-IPFS network, with only the CID code of the data kept in the node. When a user requests a piece of historical data, the node sends the corresponding CID to the IPLD component, which is used to call the original data on IPFS. If the data exists on IPFS, it is returned via the IPLD component and the node. If it does not exist, the data can not be returned.
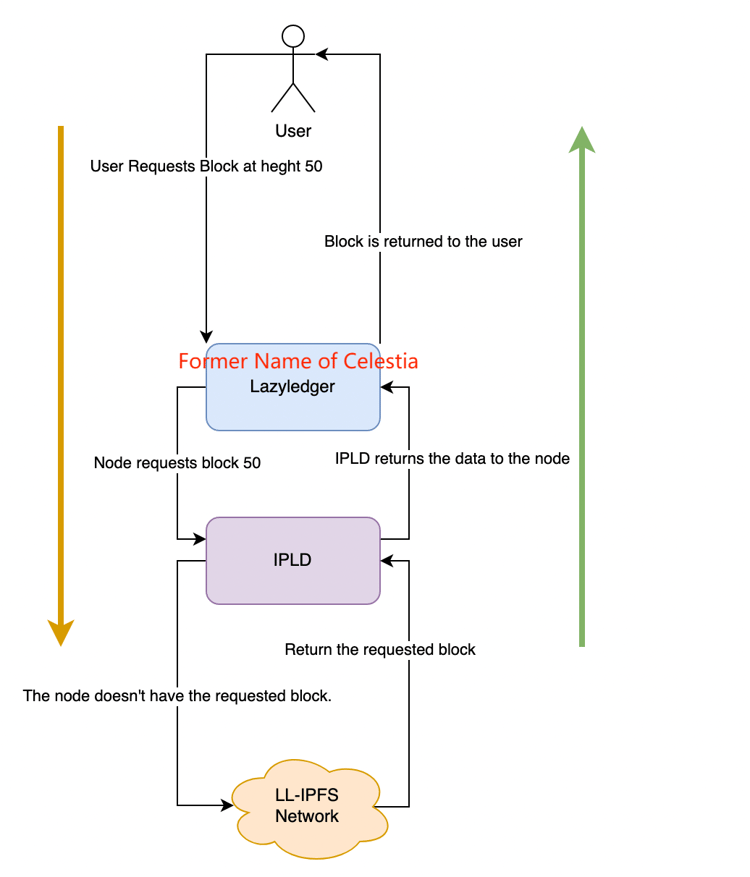
- Celestia:
Taking Celestia as an example, we can see the application of modular blockchain in solving the storage problem of Ethereum, Rollup node will send the packaged and verified transaction data to Celestia and store the data on Celestia, during the process, Celestia only stores the data without having too much perception. In this process, Celestia just stores the data without sensing it, and in the end, according to the size of the storage space, the Rollup node will pay the corresponding tia tokens to Celestia as the storage fee. The storage in Celestia utilizes a similar DAS and debugging code as in EIP4844, but the polynomial debugging code in EIP4844 is upgraded to use a two-dimensional RS debugging code, which upgrades the security of the storage again, and only 25% of the fractions are needed to recover the entire transaction data. It is essentially a POS public chain with low storage costs, and if it is to be realized as a solution to Ethereum's historical data storage problem, many other specific modules are needed to work with Celestia. For example, in terms of rollup, one of the roll-up models highly recommended by Celestia's official website is Sovereign Rollup, which is different from the common rollup on Layer2, which can only calculate and verify transactions, just completing the execution layer, and includes the entire execution and settlement process, which minimizes the need for the execution and settlement process on Celestia. This minimizes the processing of transactions on Celestia, which maximizes the overall security of the transaction process when the overall security of Celestia is weaker than that of Ethereum. As for the security of the data called by Celestia on the main network of Ethereum, the most mainstream solution is the Quantum Gravity Bridge smart contract. For the data stored on Celestia, it will generate a Merkle Root (data availability certificate) and keep it on the Quantum Gravity Bridge contract on the main network of EtherCenter. When EtherCenter calls the historical data on Celestia every time, it will compare the hash result with the Merkle Root, and if it matches, then it means that it is indeed the real historical data.
Storage Chain DA
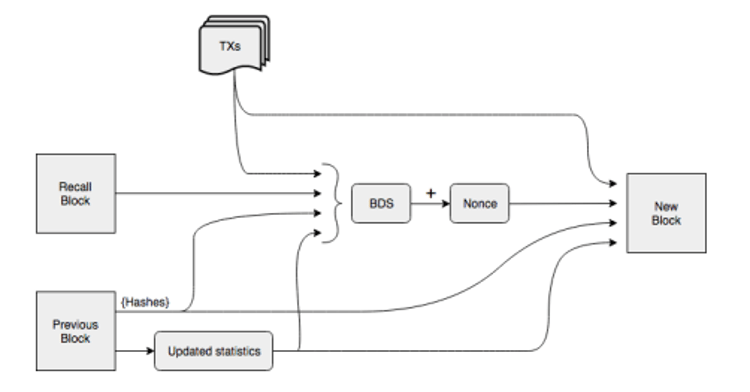
In terms of the technical principles of mainchain DAs, many techniques similar to sharding have been borrowed from storage public chains. In third-party DAs, some of them even fulfill part of the storage tasks directly with the help of storage public chains, for example, the specific transaction data in Celestia is put on the LL-IPFS network. In the solutions of third-party DAs, besides building a separate public chain to solve the storage problem of Layer1, a more direct way is to directly connect the storage public chain to Layer1 to store the huge historical data on Layer1. For high-performance blockchain, the volume of historical data is even larger, under full-speed operation, the data volume of high-performance public chain Solana is close to 4 PG, which is completely beyond the storage range of ordinary nodes. Solana chooses a solution to store historical data on the decentralized storage network Arweave and only retains 2 days of data on the nodes of the main network for verification. To ensure the security of the storage process, Solana and the Arweave chain have designed a storage bridge protocol, Solar Bridge, which synchronizes the validated data from Solana nodes to Arweave and returns the corresponding tag, which allows Solana nodes to view the historical data of the Solana blockchain at any point in time. The Solana node can view historical data from any point in time on the Solana blockchain. On Arweave, instead of requiring nodes across the network to maintain data consistency as a necessity for participation, the network adopts a reward storage approach. First of all, Arweave doesn't use a traditional chain structure to build blocks, but more like a graph structure. In Arweave, a new block will not only point to the previous block, but also randomly point to a generated block Recall block, whose exact location is determined by the hash result of the previous block and its block height, and the location of the Recall block is unknown until the previous block is mined out. However, in the process of generating new blocks, nodes are required to have the data of the Recall block to use the POW mechanism to calculate the hash of the specified difficulty, and only the miner who is the first to calculate the hash that meets the difficulty can be rewarded, which encourages miners to store as much historical data as possible. At the same time, the fewer people storing a particular historical block, the fewer competitors a node will have when generating a difficulty-compliant nonce, encouraging miners to store blocks with fewer backups in the network. Finally, to ensure that nodes store data permanently, WildFire's node scoring mechanism is introduced in Arweave. Nodes will prefer to communicate with nodes that can provide historical data more and faster, while nodes with lower ratings will not be able to get the latest block and transaction data the first time, thus failing to get a head start in the POW competition.
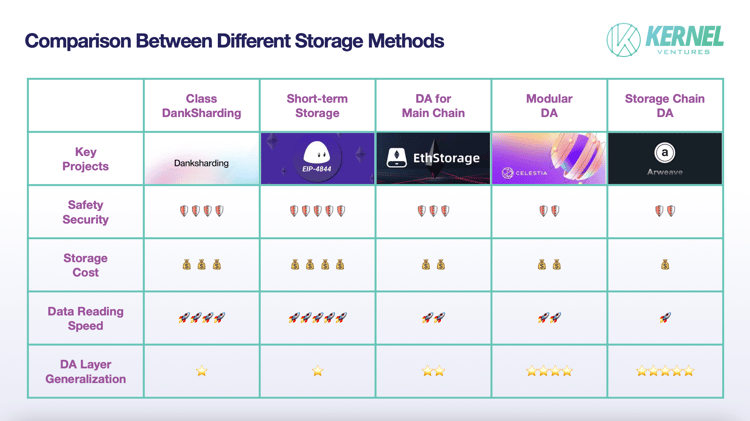
Synthesized Comparison
We will compare the advantages and disadvantages of each of the five storage solutions in terms of the four dimensions of DA performance metrics.
- Safety:
The biggest source of data security problems is the loss of data caused by the data transmission process and malicious tampering from dishonest nodes, and the cross-chain process is the hardest hit area of data transmission security due to the independence of the two public chains and the state is not shared. In addition, Layer1, which requires a specialized DA layer at this stage, often has a strong consensus group, and its security will be much higher than that of ordinary storage public chains. Therefore, the main chain DA solution has higher security. After ensuring the security of data transmission, the next step is to ensure the security of calling data. Considering only the short-term historical data used to verify the transaction, the same data is backed up by the whole network in the temporary storage network, while the average number of data backups in the DankSharding-like scheme is only 1/N of the number of nodes in the whole network, which means more data redundancy can make the data less prone to be lost, and at the same time, it can provide more reference samples for verification. Therefore, temporary storage will have higher data security. In the third-party DA scheme, because of the public nodes used in the main chain, the data can be directly transmitted through these relay nodes in the process of cross-chaining, and thus it will also have a relatively higher security than other DA schemes.
- Storage Cost:
The factor that has the greatest impact on storage cost is the amount of redundancy in the data. In the short-term storage scheme of the main chain DA, which uses the form of network-wide node data synchronization for storage, any newly stored data needs to be backed up in the network-wide nodes, having the highest storage cost. The high storage cost in turn determines that in a high TPS network, this approach is only suitable for temporary storage. Next is the sharding storage method, including sharding in the main chain and sharding in the third-party DA. Because the main chain often has more nodes, and thus the corresponding block will have more backups, the main chain sharding scheme will have a higher cost. The lowest storage cost is in the storage public chain DA that adopts the reward storage method, and the amount of data redundancy in this scheme tends to fluctuate around a fixed constant. At the same time, the storage public chain DA also introduces a dynamic adjustment mechanism, which attracts nodes to store less backup data by increasing the reward to ensure data security.
- Data Read Speed:
Data storage speed is primarily affected by where the data is stored in the storage space, the data index path, and the distribution of the data among the nodes. Among them, where the data is stored in the nodes has a greater impact on the speed, because storing the data in memory or SSD can lead to a tens of times difference in read speed. Storage public chain DAs mostly take SSD storage because the load on that chain includes not only data from the DA layer but also highly memory-hungry personal data such as videos and images uploaded by users. If the network does not use SSDs as storage space, it is difficult to carry the huge storage pressure and meet the demand for long-term storage. Second, for third-party DAs and main-chain DAs that use memory state to store data, third-party DAs first need to search for the corresponding indexed data in the main chain, and then transfer the indexed data across the chain to third-party DAs and return the data via the storage bridge. In contrast, the mainchain DA can query data directly from nodes, and thus has faster data retrieval speed. Finally, within the main-chain DA, the sharding approach requires calling blocks from multiple nodes and restoring the original data. Therefore, it is slower than the short-term storage method without sharding.
- DA Layer Universality:
Mainchain DA universality is close to zero because it is not possible to transfer data from a public chain with insufficient storage space to another public chain with insufficient storage space. In third-party DAs, the generality of a solution and its compatibility with a particular mainchain are contradictory metrics. For example, in the case of a mainchain-specific DA solution designed for a particular mainchain, it has made a lot of improvements at the level of node types and network consensus to adapt to that particular public chain, and thus these improvements can act as a huge obstacle when communicating with other public chains. Within third-party DAs, storage public chain DAs perform better in terms of generalizability than modular DAs. Storage public chain DAs have a larger developer community and more expansion facilities to adapt to different public chains. At the same time, the storage public chain DA can obtain data more actively through packet capture rather than passively receiving information transmitted from other public chains. Therefore, it can encode the data in its way, achieve standardized storage of data flow, facilitate the management of data information from different main chains, and improve storage efficiency.
Conclusion
Blockchain is undergoing the process of conversion from Crypto to Web3, and it brings an abundance of projects on the blockchain, but also data storage problems. To accommodate the simultaneous operation of so many projects on Layer1 and ensure the experience of the Gamefi and Socialfi projects, Layer1 represented by Ethereum has adopted Rollup and Blobs to improve the TPS. What's more, the n/umber of high-performance blockchains in the newborn blockchain is also growing. But higher TPS not only means higher performance but also means more storage pressure in the network. For the huge amount of historical data, multiple DA approaches, both main chain and third-party based are proposed at this stage to adapt to the growth of storage pressure on the chain. Improvements have their advantages and disadvantages and have different applicability in different contexts.
In the case of payment-based blockchains, which have very high requirements for the security of historical data and do not pursue particularly high TPS, those are still in the preparatory stage, they can adopt a DankSharding-like storage method, which can ensure security and a huge increase in storage capacity at the same time realize. However, if it is a public chain like Bitcoin, which has already been formed and has a large number of nodes, there is a huge risk of rashly improving the consensus layer, so it can adopt a special DA for the main chain with higher security in the off-chain storage to balance the security and storage issues. However, it is worth noting that the function of the blockchain is changing over time. For example, in the early days, Ethereum's functionality was limited to payments and simple automated processing of assets and transactions using smart contracts, but as the blockchain landscape has expanded, various Socialfi and Defi projects have been added to Ethereum, pushing it to a more comprehensive direction. With the recent explosion of the inscription ecosystem on Bitcoin, transaction fees on the Bitcoin network have surged nearly 20 times since August, reflecting the fact that the network's transaction speeds are not able to meet the demand for transactions at this stage. Traders have to raise fees to get transactions processed as quickly as possible. Now, the Bitcoin community needs to make a trade-off between accepting high fees and slow transaction speed or reducing network security to increase transaction speeds while defeating the purpose of the payment system in the first place. If the Bitcoin community chooses the latter, then the storage solution will need to be adjusted in the face of increasing data pressure.
8.png)
As for the public chain with comprehensive functions, its pursuit of TPS is higher, with the enormous growth of historical data, it is difficult to adapt to the rapid growth of TPS in the long run by adopting the DankSharding-like solution. Therefore, a more appropriate way is to migrate the data to a third-party DA for storage. Among them, main chain-specific DAs have the highest compatibility and may be more advantageous if only the storage of a single public chain is considered. However, nowadays, when Layer1 public chains are blooming, cross-chain asset transfer and data interaction have also become a common pursuit of the blockchain community. If we consider the long-term development of the whole blockchain ecosystem, storing historical data from different public chains on the same public chain can eliminate many security problems in the process of data exchange and validation, so the modularized DA and the way of storing public chain DAs may be a better choice. Under the premise of close generality, modular DA focuses on providing blockchain DA layer services, introduces more refined index data to manage historical data, and can make a reasonable categorization of different public chain data, which has more advantages compared with storage public chains. However, the above proposal does not consider the cost of consensus layer adjustment on the existing public chain, which is extremely risky. A tiny systematic loophole may make the public chain lose community consensus. Therefore, if it is a transitional solution in the process of blockchain transformation, the temporary storage on the main chain may be more appropriate. Finally, all the above discussions are based on the performance during actual operation, but if the goal of a certain public chain is to develop its ecology and attract more project parties and participants, it may also tend to favor projects that are supported and funded by its foundation. For example, if the overall performance is equal to or even slightly lower than that of the storage public chain storage solution, the Ethereum community will also favor EthStorage, which is a Layer2 project supported by the Ethereum Foundation, to continue to develop the Ethereum ecosystem.
All in all, the increasing complexity of today's blockchains brings with it a greater need for storage space. With enough Layer1 validation nodes, historical data does not need to be backed up by all nodes in the whole network butcan ensure security after a certain threshold. At the same time,the division of labor of the public chain has become more and more detailed, Layer1 is responsible for consensus and execution, Rollup is responsible for calculation and verification, and then a separate blockchain is used for data storage. Each part can focus on a certain function without being limited by the performance of the other parts. However, the specific number of storage or the proportion of nodes allowed to store historical data in order toachieve a balance between security and efficiency,as well as how toensure secure interoperability between different blockchainsis a problem that needs to be considered by blockchain developers. Investors canpay attention to the main chain-specific DA project on Ethereum, because Ethereum already has enough supporters at this stage, without the need to use the power of other communities to expand its influence. It is more important to improve and develop its community to attract more projects to the Ethereum ecosystem. However, for public chains that are catching up, such as Solana and Aptos, the single chain itself does not have such a perfect ecosystem, so they may prefer to join forces with other communities to build a large cross-chain ecosystem to expand their influence. Therefore,for the emerging Layer1, a general-purpose third-party DA deserves more attention.
Reference
- Celestia:模块化区块链的星辰大海:https://foresightnews.pro/article/detail/15497
- DHT usage and future work:https://github.com/celestiaorg/celestia-node/issues/11
- Celestia-core:https://github.com/celestiaorg/celestia-core
- Solana labs:https://github.com/solana-labs/solana?source=post_page-----cf47a61a9274--------------------------------
- Announcing The SOLAR Bridge:https://medium.com/solana-labs/announcing-the-solar-bridge-c90718a49fa2
- leveldb-handbook:https://leveldb-handbook.readthedocs.io/zh/latest/sstable.html
- Kuszmaul J. Verkle trees[J]. Verkle Trees, 2019, 1: 1.:https://math.mit.edu/research/highschool/primes/materials/2018/Kuszmaul.pdf
- Arweave 官网:https://www.arweave.org/
- Arweave 黄皮书:https://www.arweave.org/yellow-paper.pdf
Layer 1
Ethereum
Disclaimer
For questions & inquiries
info@tokeninsight.com
For research & editorial
research@tokeninsight.com
2018 – 2026 © TokenInsight Ltd. All rights reserved

Use TokenInsight App All Crypto Insights Are In Your Hands
Open