

 이더리움 가상 머신(Ethereum Virtual Machine)은 이더리움 블록체인에 구축된 코드 운영 환경입니다. 계약 코드는 외부에서 완전히 격리되어 EVM 내부에서 실행될 수 있습니다. 그 주요 기능은 이더리움 시스템에서 스마트 계약을 처리하는 것입니다. 이더리움이 Turing-complete인 이유는 개발자들이 Solidity 언어를 사용하여 EVM에서 실행되는 애플리케이션을 만들 수 있고, 모든 계산 가능한 문제를 계산할 수 있기 때문입니다. 그러나 튜링 완전성만으로 충분하지 않습니다. 사람들은 또한 EVM을 ZK-proof 시스템에 캡슐화하려고 시도하지만, 캡슐화할 때 많은 중복이 발생할 수 있습니다. Fox가 개발한 "소형 테이블 모드"(Small Table Mode) zkEVM은 솔리디티 Ethereum 개발자가 zkEVM로의 이주를 원활하게 할 뿐만 아니라, EVM을 ZK-proof 시스템으로 패키징하는 중복 비용을 크게 줄일 것입니다.
이더리움 가상 머신(Ethereum Virtual Machine)은 이더리움 블록체인에 구축된 코드 운영 환경입니다. 계약 코드는 외부에서 완전히 격리되어 EVM 내부에서 실행될 수 있습니다. 그 주요 기능은 이더리움 시스템에서 스마트 계약을 처리하는 것입니다. 이더리움이 Turing-complete인 이유는 개발자들이 Solidity 언어를 사용하여 EVM에서 실행되는 애플리케이션을 만들 수 있고, 모든 계산 가능한 문제를 계산할 수 있기 때문입니다. 그러나 튜링 완전성만으로 충분하지 않습니다. 사람들은 또한 EVM을 ZK-proof 시스템에 캡슐화하려고 시도하지만, 캡슐화할 때 많은 중복이 발생할 수 있습니다. Fox가 개발한 "소형 테이블 모드"(Small Table Mode) zkEVM은 솔리디티 Ethereum 개발자가 zkEVM로의 이주를 원활하게 할 뿐만 아니라, EVM을 ZK-proof 시스템으로 패키징하는 중복 비용을 크게 줄일 것입니다.
By: Frederick Kang, CEO of Fox Tech; Alan Lin, CTO of Fox Tech
EVM은 2015년에 처음 시작된 이후로 엄청난 ZK 변환을 겪고 있습니다. 이 주요한 변환은 두 가지 주요 방향을 가지고 있습니다.
첫 번째 방향은 "zkVM 트랙"이라고 불리는 것입니다. 이 트랙 프로젝트는 응용 프로그램의 성능을 최적화하고, 이더리움 가상 머신과의 호환성은 주된 고려 요소가 아닙니다. 여기에는 두 가지 하위 방향이 있습니다. 하나는 자체 DSL(도메인 특화 언어)을 만드는 것입니다. 예를 들어, StarkWare는 적극적으로 Cairo 언어를 홍보하는데 힘쓰고 있습니다. 두 번째는 기존 상대적으로 성숙한 언어와 호환성을 갖는 것을 목표로 합니다. 예를 들어, RISC Zero는 zkVM을 C++ 및 Rust와 호환되도록 만들기 위해 노력하고 있습니다. 이 트랙의 어려움은 명령 집합 ISA의 도입으로 인해 최종 출력 제약이 더 복잡해진다는 점입니다.
두 번째 방향은 "zkEVM 트랙"이라고 불리는 것입니다. 이 트랙 프로젝트는 EVM 바이트코드의 호환성에 전념하며, 즉, 바이트코드 수준에서의 EVM 코드 및 상위 모든 코드에 대한 일치하는 제로지식 증명을 zkEVM을 통해 생성함으로써 네이티브 Solidity 이더리움 개발자들이 비용 부담 없이 zkEVM으로 이전할 수 있도록 합니다. 이 트랙의 참가자들은 주로 Polygon zkEVM, Scroll, Taiko, 그리고 Fox가 포함됩니다. 이 트랙의 어려움은 EVM과 호환된다는 것이며, ZK-증명 시스템에서 장황성 비용을 캡슐화하는 데 적합하지 않다는 것입니다. 오랜 시간을 들여 고민하고 논쟁한 끝에 Fox는 첫 번째 세대 zkEVM의 엄청난 장황성을 근본적으로 줄이는 열쇠를 발견했습니다: "소표 모듈" zkEVM입니다.
증거 회로와 데이터는 zkEVM의 증거를 생성하기 위한 두 가지 핵심 요소입니다. 한편 zkEVM에서는 증명자가 거래에 관련된 모든 데이터가 올바른 상태 전이를 증명하기 위해 필요하며, EVM의 데이터는 대규모이며 복잡한 구조를 갖고 있습니다. 따라서, 증명을 위해 필요한 데이터를 조직하고 구성하는 방법은 효율적인 zkEVM을 구축하기 위해 신중히 고려해야 하는 문제입니다. 다른 한편에서는 일련의 회로 제약 조건을 통해 계산 실행의 유효성 및 올바름을 효율적으로 증명(또는 검증)하는 것이 zkEVM의 안정성을 보장하기 위한 기초입니다.
이제 첫 번째로 논할 질문에 대해 이야기해 보겠습니다, 이는 zkEVM을 설계한 모든 팀들이 고려해야 할 질문입니다. 이 질문의 본질은 실제로 "우리가 무엇을 증명하고 싶은가?"입니다. 현재 이 질문에 대한 모든 사람의 생각은 유사합니다, 왜냐하면 트랜잭션(또는 관련되는 오프코드)은 다양할 수 있으며, 각 단계의 작업이 가져오는 상태 변화를 직접 증명하는 것은 현실적이지 않기 때문에 분류적 증명이 필요합니다.

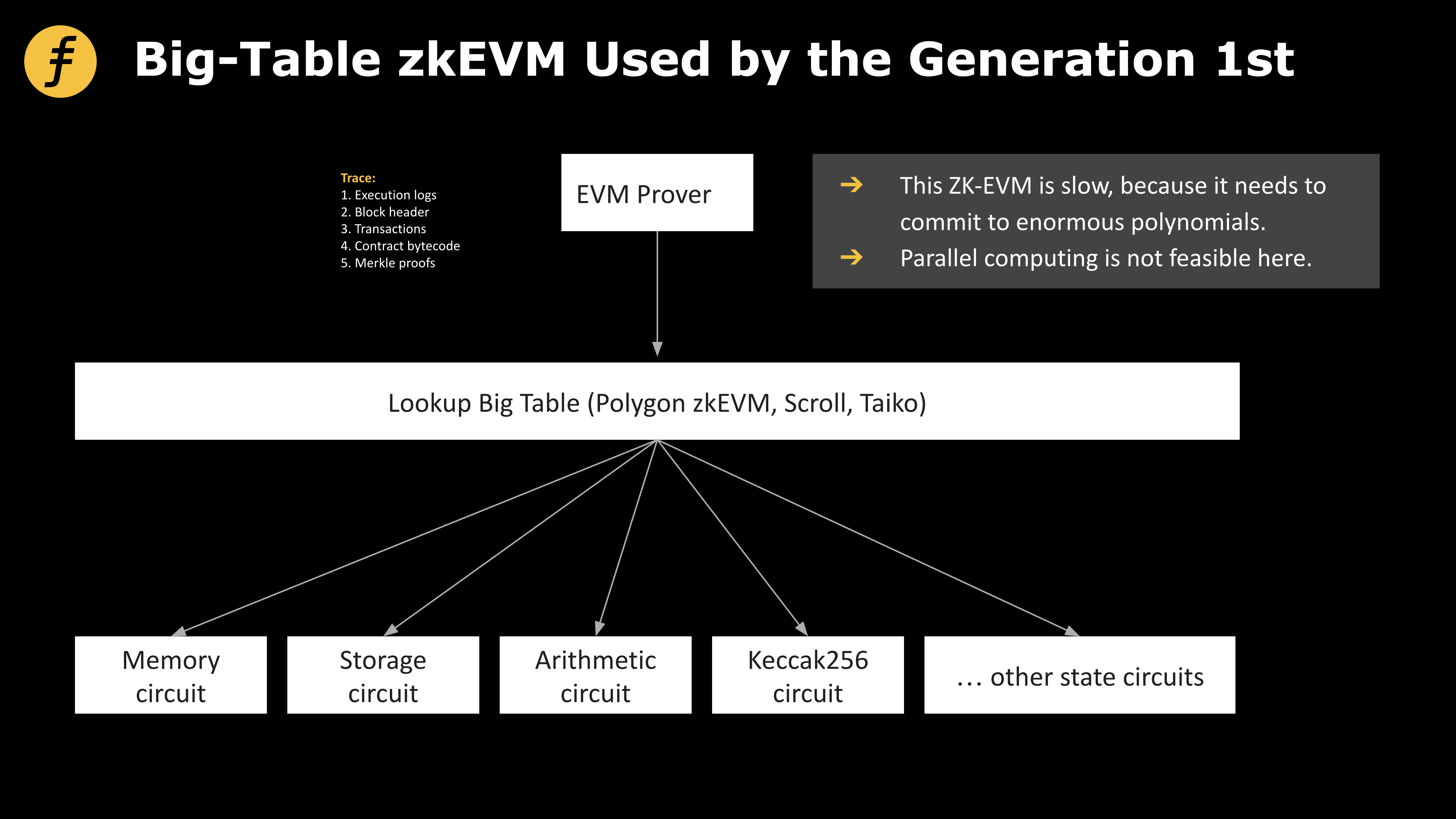
예를 들어, 스택에 원소들의 각 변경을 모아 스택 회로 증명을 특별히 작성하거나, 순수한 산술 연산을 위해 산술 회로 세트를 작성하는 등, 다양한 기능을 하는 이러한 회로들은 다른 zkEVM에서 다른 이름을 가지고 있다. 일부 사람들은 이를 단순히 회로라고 부르고, 다른 사람들은 (서브)상태 기계라고 부르지만, 이 아이디어의 본질은 같다.
이를 더 명확히 설명하기 위해 다음과 같은 예를 들어 보겠습니다. 지금 우리가 덧셈 작업을 증명하려고 한다고 가정해 보겠습니다 (스택의 상위 2개 원소를 꺼내서 그들의 합을 다시 스택의 맨 위에 넣는다):
원래 스택이 [1,3,5,4,2]라고 가정해 봅시다.
그렇다면 분류와 분할을 하지 않으면, 우리는 위 작업 후 스택이 [1,3,5,6]이 됨을 증명하기 위해 노력해야 합니다.
분류와 분할할 경우, 우리는 다음을 별도로 증명할 필요가 있습니다:
스택 회로:
- C1: 2와 4를 팝하여 [1,3,5,4,2]가 [1,3,5]가 되는 것을 증명
- C2: push(6) 후 [1,3,5]가 [1,3,5,6]이 되는 것을 증명
산술 회로:
- C3: a=2, b=4, c=6, a+b=c를 증명
증명의 복잡성은 회로가 고려해야 하는 상황의 수와 관련이 있음을 유의해야 합니다. 분류와 분할을 하지 않는 경우, 회로가 커버해야 할 가능성이 엄청 클 것입니다.
분류와 분할 후 각 부분의 상황은 상대적으로 간단해지므로, 증명의 난이도는 상당히 감소할 것입니다.
하지만 분류와 분할은 다른 문제를 야기할 수도 있습니다. 즉, 다른 유형의 회로들 사이의 데이터 일관성 문제입니다. 예를 들어, 위의 예에서 다음을 증명해야 합니다:
- C4: "C1에서 팝된 숫자" = "C3의 a 및 b"
- C5: "C2에서 푸시된 숫자" = "C3의 c"
이 문제를 해결하기 위해 우리는 첫 번째 질문으로 돌아가야 합니다, 즉 거래에 관련된 데이터를 어떻게 조직할 것인가, 그리고 다음에 이 주제에 대해 논의하겠습니다:
한 가지 직관적인 방법은 다음과 같습니다: 트레이스를 통해 모든 거래에 관련된 각 단계를 분해하여, 관련된 데이터를 알고 미궁의 데이터를 가져오기 위해 노드에 요청을 보내고, 그리고 우리가 다음과 같이 큰 테이블 T로 배열할 것입니다:
"첫 번째 단계 작업" "첫 번째 단계 작업에 관련된 데이터"
"두 번째 단계 작업" "두 번째 단계 작업에 관련된 데이터"
…
"n번째 단계 작업" "n번째 단계 작업에 관련된 데이터"”
그래서 위의 예제에서 우리는 기록하는 라인을 가지게 됩니다
"단계 k: 추가" “a=2, b=4, c=6”
위의 C4는 다음과 같이 증명될 수 있습니다:
- C4(a): C1에 의해 팝된 숫자가 큰 테이블 T의 k단계와 일치합니다
- C4(a): C3의 a와 b가 큰 테이블 T의 k단계와 일치합니다
C5도 유사합니다. 이 작업(어떤 요소가 테이블에 나타나는지 증명하는 것)을 룩업이라고 합니다. 우리는 이 기사에서 룩업의 구체적인 알고리즘을 소개하지 않겠지만, 룩업 작업의 복잡성이 큰 테이블 T의 크기와 밀접한 관련이 있다는 것은 상식적으로 이해할 수 있습니다. 그래서 이제 첫 번째 질문으로 돌아가서, 증명에 사용될 데이터를 어떻게 구성해야 할까요?
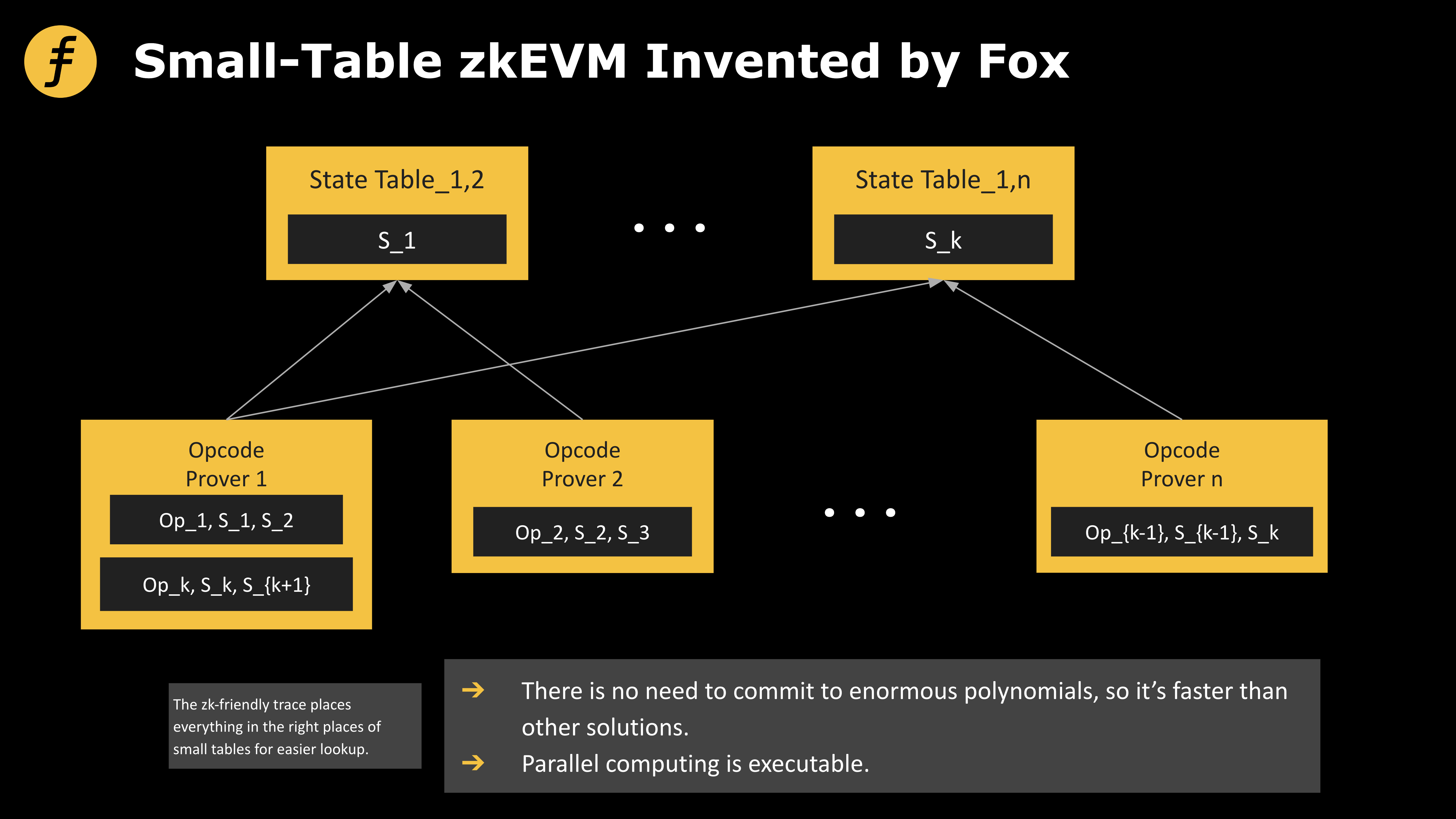
다음 시리즈의 테이블 구성을 고려해 봅시다:
Ta 형태:
"a 유형의 첫 번째 작업" "a 유형의 첫 번째 작업에 관련된 데이터"
"a 유형의 두 번째 작업" "a 유형의 두 번째 작업에 관련된 데이터"
…
"a 유형의 m번째 작업" “a 유형의 m번째 작업에 관련된 데이터”
Tb 형태:
"b 유형의 첫 번째 작업" "b 유형의 첫 번째 작업에 관련된 데이터"
"b 유형의 두 번째 작업" "b 유형의 두 번째 작업에 관련된 데이터"
…
"b 유형의 m번째 작업" "b 유형의 m번째 작업에 관련된 데이터"
…
이렇게 여러 작은 테이블을 구성하는 장점은 필요한 데이터에 관련된 작업 유형에 따라 해당 작은 테이블에서 직접 룩업을 수행할 수 있다는 것입니다. 이렇게 하면 효율성이 크게 향상될 수 있습니다.
간단한 예시(한 번에 하나의 요소만을 조회할 수 있다고 가정한 경우)는 [a,b,c,d,e,f,g,h]에 8개의 문자 a~h가 존재하는 것을 증명하려면 크기가 8인 테이블에서 8번의 조회를 해야하지만, 테이블을 [a,b,c,d]와 [e,f,g,h]로 나누면 두 테이블에서 이를 각각 4번씩 조회할 수 있습니다!
이 작은 테이블의 설계는 FOX의 2계층 zkEVM에서 효율성을 향상시키기 위해 사용됩니다. 다양한 상황에서 완전한 증명을 보장하기 위해 구체적인 작은 테이블 분할 방법은 신중하게 설계되어야 하며, 효율성 향상의 핵심은 표의 내용을 분류하는 것과 그 크기를 균형있게 유지하는 것입니다. 이 프레임워크에서 완전한 zkEVM을 구현하는 데는 많은 노력이 필요하지만, 이러한 zkEVM이 성능에서 돌파구를 찾을 것이라 기대합니다.
결론: Fox가 개발한 "작은 테이블 모드" zkEVM는 네이티브 Solidity 이더리움 개발자가 무료로 zkEVM으로 이주할 수 있도록 보장하는 동시에 EVM을 ZK 증명 시스템으로 캡슐화하는 불필요한 비용을 크게 줄입니다.
이것은 zkEVM의 구조적 큰 변화이며, Ethereum의 확장 계획에 깊은 영향을 미칠 것입니다. 앱으로
앱으로
